Fragmented data usually shows up as a business problem long before it looks like a technology problem. Teams chase different numbers, managers wait for manual reports, and decisions slow down because no one trusts the same version of reality. This article explains what breaking down data silos really involves, why it matters for strategy and change, and how to build the leadership, governance, and habits that make shared data work.
The essentials for building shared data trust
- Data silos are not just separate systems; they are separate definitions, ownership rules, and access habits.
- The fastest gains come from one high-value workflow, not an enterprise-wide cleanup campaign.
- Shared data only sticks when business leaders, not just IT, own the standards and exceptions.
- Inclusive leadership matters because people share problems sooner when they feel safe challenging bad numbers.
- I would measure progress by decision speed, duplicate reports retired, and the number of shared definitions that are actually used.
What data silos are really costing you
A silo is not just a database sitting in the wrong place. It is any setup that keeps one team’s data from being understood, trusted, or reused by another team. When sales, HR, finance, and operations each work from a different version of the truth, the organization spends time arguing about the numbers instead of acting on them.
That shows up in slow reporting, duplicated effort, inconsistent customer or employee experiences, and more rework in everything from planning to compliance. McKinsey’s work on master data management makes the point clearly: the most important information about customers, suppliers, products, and employees has to be easy to organize and access across functions. When that does not happen, the cost is not abstract. It becomes missed handoffs, bad decisions, and avoidable friction for both employees and customers.
I also see a quieter cost that leaders underestimate: people stop trusting shared reporting and start building their own shadow dashboards. Once that happens, the organization does not just have a data problem. It has a coordination problem. That is why the next question is not about tools alone, but about how the change itself is managed.
Why this is a strategy and change problem
I do not see silo problems survive because people like bad data. They survive because each department optimizes for its own goals, tools, and risk tolerance. In a U.S. organization, that can mean sales wants speed, HR wants confidentiality, finance wants control, and operations wants consistency. All of those priorities are valid, but they create friction when nobody is responsible for the shared picture.
In 2026, the pressure is sharper because usable data now sits at the center of AI, planning, and operational speed. Gartner predicts that through 2026, organizations will abandon 60% of AI projects unsupported by AI-ready data. I think that is useful here because it reveals the deeper issue: AI does not create the silo problem, it exposes it faster.
There is also a human side to this. If people are punished for surfacing bad data, they will quietly work around it. If they do not feel heard when a metric is wrong, they will stop challenging it. I would rather have a team that says, “this number is wrong,” than one that hides uncertainty until it reaches the board deck. That is why the fix has to combine governance, process, and culture.
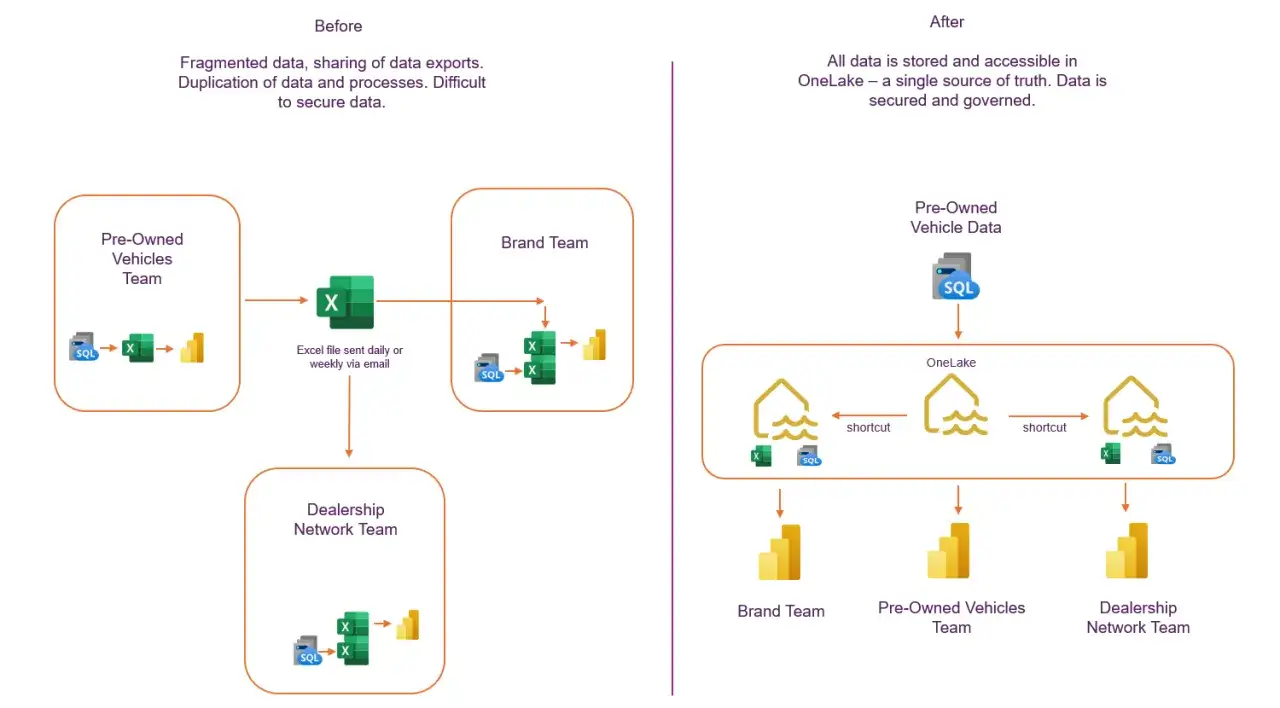
The operating model that actually removes the barriers
I would not start with a platform purchase. I would start by deciding which data must be shared, who owns it, and how people can use it without creating a compliance mess. A single source of truth does not mean one giant database. It means one governed version of a critical record that the organization agrees to use.
| Element | What it does | Common mistake |
|---|---|---|
| Shared definitions | Creates one agreed meaning for core metrics and entities | Letting each team define churn, headcount, or active customer differently |
| Named owners | Makes someone accountable for the dataset and its changes | Leaving ownership to a committee with no real decision rights |
| Data catalog | Gives people a searchable inventory of approved data, definitions, and owners | Building it once and never curating it again |
| Integration layer | Connects systems so people are not forced into manual exports | Depending on spreadsheets and copy-paste workflows |
| Access controls | Sets role-based access and audit trails for sensitive data | Making access so hard that teams create shadow copies |
| Data quality monitoring | Checks freshness, completeness, and structural changes before they spread | Only fixing quality after dashboards break |
That mix is usually more effective than a full centralization push. I prefer to standardize the most reused data first, especially customer, employee, product, or finance records, and then connect the rest around those core assets. It is also where data governance matters. Data governance is simply the set of rules for who owns data, who can change it, and how quality is maintained. Without it, “shared” data turns into shared confusion.
The practical takeaway is simple: focus on the records and metrics that many teams depend on, and give them clear rules before you expand the model. Tools help, but they only work when leaders change the social contract around data.
How inclusive leadership keeps the change from stalling
I treat inclusive leadership here as an operating behavior, not a values poster. The point is to bring the people who use, interpret, and maintain the data into the conversation early enough that they can shape the rules. That matters because silos often hide inside status gaps. If analysts, frontline managers, HR partners, and finance teams do not feel heard, they will keep their own workarounds.
The strongest leaders I see do a few things consistently:
- They invite the teams that rely on the data to help define the metric before it is published.
- They make it normal to challenge a dashboard, ask for a source, or flag a missing field.
- They publish decisions and exceptions so nobody has to guess how the standard was created.
- They recognize the people who expose messy data early, because that reduces risk instead of creating noise.
- They separate voice from veto, so everyone is heard even when not every input becomes the rule.
This is where workplace culture and data strategy meet. People share better data when they know the messenger will not be blamed for the message. That does not mean consensus on everything. It means enough trust to surface problems quickly and enough clarity to act on them. Once that culture is in place, a phased rollout can actually stick.
A rollout plan that creates momentum without a big-bang rebuild
I prefer a 90-day pilot because it is long enough to reveal friction and short enough to keep urgency. Big-bang transformations often fail because they try to fix everything at once and end up fixing nothing well enough.
- Pick one workflow with visible pain, such as employee onboarding, customer service, or finance close.
- Map the systems, the handoffs, the definitions, and the person who can change each one.
- Agree on three to five shared metrics and the minimum access rules needed to use them.
- Fix the highest-value master data first, then connect the rest of the source systems.
- Review progress every month with business, IT, compliance, and the teams who actually use the data.
I would keep the pilot narrow enough that people can see the win. If the organization can answer one important question faster and with less debate, confidence starts to build. From there, scaling becomes a matter of repeating the pattern, not recreating the entire project.
The point is not to prove that the architecture is perfect. The point is to prove that shared data saves time and lowers friction. If the pilot works, scale the pattern rather than copy the exact setup.
The mistakes that keep silos alive
I have seen well-funded data programs stall because the organization fixed the wrong layer first. The most common mistakes are predictable, which is frustrating, because they are also avoidable.
- Buying software too early: if nobody agrees on definitions, a new platform just moves confusion faster.
- Starting with technology instead of business questions: people care more about the decisions they need to make than the architecture diagram.
- Centralizing everything: not every dataset deserves enterprise-wide control, and overcentralization often creates a bottleneck.
- Leaving governance without business ownership: rules without owners become suggestions.
- Measuring volume instead of value: moving more data is not the same as making better decisions.
- Ignoring change fatigue: if the new process feels heavier than the old workaround, teams will quietly revert.
I also think leaders underestimate the cost of local incentives. A team that is rewarded for speed will not naturally slow down to standardize unless the new process is clearly better. That is why I keep coming back to adoption, not just architecture. The best check is simple: can more people answer the question they need without creating a second spreadsheet?
The metrics that tell me the silos are really shrinking
I would keep the scorecard short. Five to seven measures are enough if they reflect both speed and trust. The goal is to see whether the organization is actually making data easier to use, not just easier to store.
| Metric | What I want to see | Why it matters |
|---|---|---|
| Time to find trusted data | Falls over time | Shows whether people still need to chase information across teams |
| Shared KPI adoption | One definition used across functions | Reduces debates about whose numbers are “right” |
| Duplicate reports retired | Shadow dashboards decline | Indicates that trust is moving into shared assets |
| Access request cycle time | Approved access arrives faster | Shows that controls are workable, not just restrictive |
| Critical data quality incidents | Fewer recurring issues | Confirms that ownership and monitoring are doing their job |
| Cross-functional decision cycle time | Shared decisions move faster | Proves the change is affecting strategy, not just storage |
If AI is part of the roadmap, I would add one more measure: how often projects stall because the underlying dataset is incomplete, stale, or locked in the wrong system. That is the real test of readiness. In the end, breaking down data silos is a change effort: if the process does not make collaboration easier, faster, and safer, the organization will drift back to old habits. The goal is not perfect centralization; it is a workplace where people can find the right information, use it confidently, and make better decisions together.